はじめに #
LAM(Large Action Model)というものを初めて知りました。2024年のCESで Rabbit という会社が製品に組み込んだことで話題になったそうです。もう1年半も前の出来事なんですね。
LAMとは「アクションを行うことができるモデルで、あらゆるインタフェースを理解し人間のように自由に作業ができる」モデルです。例えば「人間の代わりにUberを呼んだり」「スプレッドシートを更新する」ようなことができるそうです。
Of course, you can tweak it to do some actions if you give it a good prompt and pass some APIs 😉 but it takes some hard work.
という記載があり、LLMでもやればできるけどめんどいよね。ということでしょうか。個人的にはLAMというキーワードを聞いたことがありませんでした。LLMとFunctionCallingやMPCなどの連携が、親和性が高く、ある程度のことができるために今はそちらが流行っているのかもしれません。
以下でLAM(rabbit intern)に触ってみたので興味があればこちらも参照ください。
もうちょっとLAMについて調べてみます。以下の記事が詳しそうなので訳していきます。
大規模アクションモデル:言語を超えて行動へ #
大型アクションモデル(LAMs)は、言語理解、推論、行動実行を通じてAIを革新しています。本ガイドでは、LAMsの概要、その能力、そしてさまざまな業界に与える変革について解説します。
大型アクションモデル(LAMs)は、指示を理解し、それに基づいて複雑なタスクや行動を実行することを目的としたディープラーニングモデルです。LAMs は、言語理解に加え、推論やソフトウェアエージェントとの統合も行います。
まだ研究開発段階にありますが、これらのモデルはAI分野において大きな変革をもたらす可能性があります。LAMs は、単なる文章生成や理解を超えた大きな進歩を示しており、私たちの働き方や多くの業界におけるタスクの自動化を根本的に変える可能性を秘めています。
大型アクションモデル(LAMs)とは何か、そしてどのように機能するのか? #
大型アクションモデル(LAMs)は、ユーザーから与えられた指示をもとにエージェントを使って行動を実行するAIソフトウェアです。タスクを階層的に分解し、小さなサブタスクに分けて進める仕組みを持っています。
大規模言語モデル(LLMs)とは異なり、LAMs は言語理解に加えて論理的推論を組み合わせ、さまざまなタスクを実行できます。このアプローチは、フィードバックや対話から学習することが多いですが、強化学習とは別物です。
より高度なLAMsの開発には「ニューロシンボリックプログラミング」という手法が重要な役割を果たしています。これは、ニューラルネットワークの学習能力とシンボリックAIの論理的推論を組み合わせた技術です。これにより、LAMs は言語を理解し、行動を推論し、指示に基づいて実行できるようになります。
LAMs のアーキテクチャは、対応できるタスクの幅広さによって異なります。ただし、その構成要素を理解する前に、LAMs と LLMs の違いを知っておくことが重要です。
| 特徴 | 大規模言語モデル (LLMs) | 大規模アクションモデル (LAMs) |
|---|---|---|
| できること | 言語生成 | タスクの実行と完了 |
| 入力 | テキストデータ | テキスト、画像、指示など |
| 出力 | テキストデータ | アクション、テキスト |
| トレーニングデータ | 大規模なテキストデータ | テキスト、コード、画像、アクション |
| 応用分野 | コンテンツ作成、翻訳、チャットボット | 自動化、意思決定、複雑なインタラクション |
| 長所 | 言語理解、テキスト生成 | 推論、計画、意思決定、リアルタイムの対話 |
| 短所 | 限定的な推論、アクション能力の欠如 | まだ開発中、倫理的な懸念 |
ここで、大型アクションモデル(LAMs)の具体的な構成要素を詳しく見ていきます。主な構成要素は以下の通りです。
- パターン認識:ニューラルネットワーク データや指示のパターンを理解するために使われます。
- シンボリックAI:論理的推論 推論や論理判断を行う役割を担います。
- アクションモデル:タスク実行(エージェント) 指示に基づいて実際にタスクを実行します。
ニューロシンボリックプログラミング #
ニューロシンボリックAIは、パターンを学習するニューラルネットワークの能力と、シンボリックAIの推論手法を組み合わせることで、両者の弱点を補い合う強力なシナジーを生み出します。
シンボリックAIは、基本的には多数の if-then ステートメントに基づく論理プログラミングを用いており、推論や意思決定の説明に優れています。知識を表現するために一階述語論理などの形式言語を使用し、ユーザーの問いに基づいて論理的な結論を導く推論エンジンを持っています。
:::message 自分の解釈 シンボリックAIでは、現実の情報(例:人、動物、関係)を「論理式」というルールで表します。そして、その論理式を使ってユーザーからの質問に対して、論理的に正しい答えを自動的に導く仕組み(推論エンジン)を持っています。例えば以下
「すべての人は死ぬ」→ ∀x Human(x) → Mortal(x) 「ソクラテスは人」→ Human(Socrates) 「ソクラテスは死ぬ?」と聞くと、 ルールに当てはめて自動で「ソクラテスは人 → 死ぬ」と推論する
この時の「人」や「死ぬ」をシンボルと捉えるようです。 :::
このように、出力をプログラム内のルールや知識に遡って説明できる点で、シンボリックAIモデルは非常に解釈性が高く、説明可能です。さらに、新しい情報が得られるたびにシステムの知識を拡張できるという利点もあります。
しかし、このアプローチだけでは以下のような限界があります。
- 新しいルールを追加しても、古い知識が自動的に修正されない
- シンボルが実際の表現や生データに結びついていない
一方、ニューロシンボリックプログラミングにおける「ニューラル」側では、LLM やビジョンモデルのような深層ニューラルネットワークを使います。これらは大量データから学習し、パターン認識に優れています。
このパターン認識能力により、ニューラルネットワークは画像分類、物体検出、自然言語処理における次の単語予測などを実現できます。ただし、シンボリックAIのような明示的な推論、論理性、説明可能性は持ちません。
ニューロシンボリックAIは、これら2つの方法(ニューラルネットワークとシンボリックAI)を統合することを目指しており、大型アクションモデル(LAMs)のような技術を生み出しています。 これらのシステムは、ニューラルネットワークの強力なパターン認識能力とシンボリックAIの推論能力を組み合わせることで、抽象的な概念について推論し、説明可能な結果を生成することができます。
ニューロシンボリックAIのアプローチは、大きく2つに分類されます。
- 構造化されたシンボリック知識を圧縮し、ニューラルネットワークのパターンに統合できる形式に変換する方法。これにより、モデルは統合された知識を使って推論できます。
- ニューラルネットワークが学習したパターンから情報を抽出し、その情報を構造化されたシンボリック知識に対応付ける方法(これを「リフティング」と呼びます)。その後、シンボリック推論に活用します。
:::message
自分の解釈
ニューロシンボリックAIは、論理式で表された制御をニューラルネットと組み合わせることで、説明可能な結果を生成できるLAMを生み出した。昨今のLLMでは Reasoning という回答の理論的背景を説明し、回答を改善する仕組みがありますが、それはやはりLLMのようなニューラルネットワークであり、シンボリックAIのような論理的なガードレールの機能は果たしません。
:::
アクションエンジン #
大型アクションモデル(LAMs)では、ニューロシンボリックプログラミングによって、LLM のようなニューラルモデルにシンボリックAIの推論や計画能力が組み込まれています。
AIエージェントの基本的な考え方は、生成した計画を実行し、新たな課題に適応することにあります。オープンソースのLAMsでは、論理プログラミングをビジョンモデルや言語モデルと統合し、ソフトウェアをさまざまなアプリやサービスのツール・APIと接続してタスクを実行できるようにしています。
ここで、これらのAIエージェントがどのように機能するのか見ていきましょう。
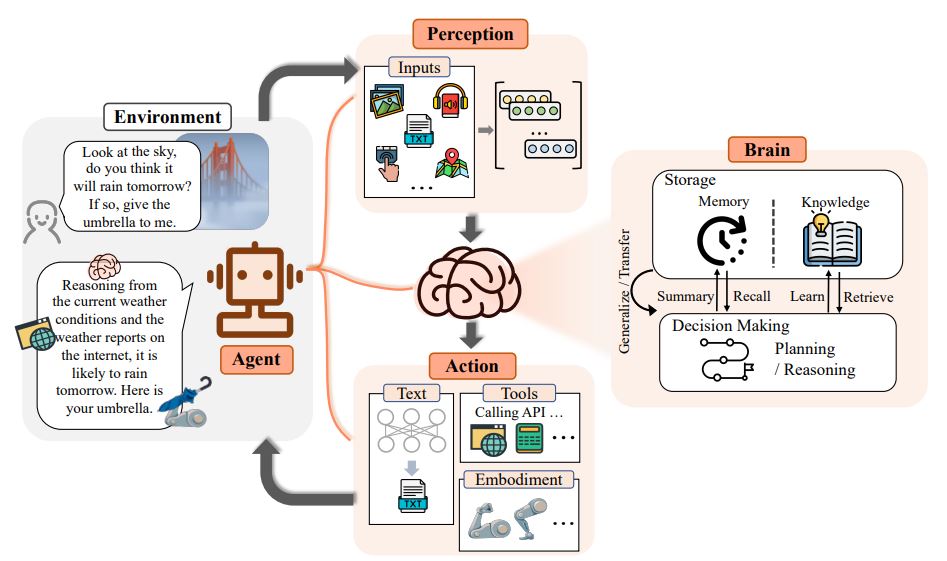
AIエージェントとは、環境を理解し、行動を起こせるソフトウェアのことです。行動は、現在の環境の状態や与えられた条件・知識に基づいて決まります。さらに、一部のAIエージェントは変化に適応し、対話を通じて学習することもできます。
上の図を参考にしながら、大型アクションモデルが私たちのリクエストをどのように実行に移すのかを見ていきましょう。
-
知覚(Perception):LAMは音声、テキスト、画像などの入力を受け取り、それにタスクのリクエストが付随します。
-
頭脳(Brain):これが大型アクションモデルのニューロシンボリックAI部分にあたり、計画、推論、記憶、知識の学習や呼び出しなどの能力を含みます。
-
エージェント(Agent):ユーザーインターフェースやデバイスとして、LAMが実際に行動を起こす部分です。受け取った入力を「頭脳」で分析し、その結果に基づいて行動します。
-
アクション(Action):ここから「実行」が始まります。テキストや画像を生成したり、実際の行動を組み合わせて出力します。例えば、LLMのテキスト生成能力で質問に答え、シンボリックAIの推論能力を使って次の行動を決定します。行動はタスクを小さなサブタスクに分解し、それぞれをAPI呼び出しやアプリ、ツール、サービスの活用などを通じて順に実行します。
Large Action Modelで何ができる? #
大型アクションモデル(LAMs)は、訓練された範囲内であればほとんどどんなタスクでも実行できます。人間の意図を理解し、複雑な指示に応答することで、単純な作業から複雑な作業まで自動化でき、テキストや画像入力に基づいて意思決定を行えます。さらに重要なのは、多くのLAMsが「説明可能性」を備えており、推論の過程をたどれる点です。Rabbit R1 は最も有名な大型アクションモデルの一つであり、そのパワーを示す代表的な例です。Rabbit R1 は以下を組み合わせています。
- 視覚タスク
- サービスやアプリケーションを接続するためのウェブポータル、および「ティーチモード」で新しいタスクを追加する機能。
- ティーチモードでは、ユーザーが自分でタスクを実行することでモデルに指示・学習させることができます。
「Large Action Models」という用語自体はすでに存在しており、研究開発が進められていましたが、Rabbit R1 とそのOSがこの概念を一般に広めました。オープンソースの代替モデルも存在しており、これらは多くの場合、論理プログラミングやビジョン/言語モデルの原理を取り入れ、APIと連携し、ユーザーのリクエストに基づいてアクションを実行する仕組みを持っています。
オープンソースLAMモデル #
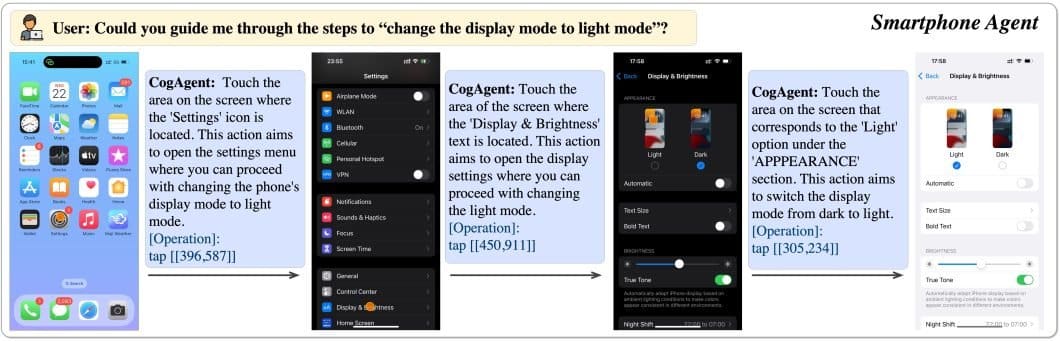
- CodeAgent CogAgent は、オープンソースのビジョン言語モデルである CogVLM を基にしたオープンソースのアクションモデルです。これは視覚エージェントであり、計画の生成、次のアクションの決定、指定されたGUIスクリーンショット内での正確な操作座標の提供が可能です。さらに、このモデルは任意のGUIスクリーンショットに対する視覚的質問応答(VQA)やOCR関連タスクも実行できます。
- Gorilla Gorilla は、LLM に正確なAPIコールを通じて数千のツールを使わせることができる、非常に優れたオープンソースの大型アクションモデルです。自然言語のクエリから必要なアクションを理解し、適切なAPIコールを特定・実行します。このアプローチにより、1,600以上(現在も増加中)のAPIを高精度で呼び出すことに成功しており、幻覚(誤った出力)も最小限に抑えています。
Gorilla は独自の実行エンジン「GoEx」を使用しており、これがコード実行やAPIコールなど、LLMが生成した計画を実行するためのランタイム環境として機能します。
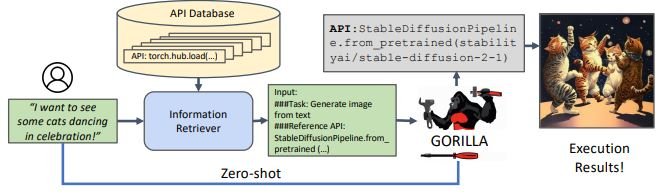
上の図は、大型アクションモデルが実際に動作している分かりやすい例を示しています。ここでは、ユーザーが特定の画像を見たいとリクエストすると、モデルは知識データベースから必要なアクションを取得し、APIコールを通じて必要なコードを実行します。これらはすべてゼロショット(事前の個別学習なし)で行われます。
LAMの実利用 #
大型アクションモデル(LAMs)の力はさまざまな産業に広がり、私たちの技術との関わり方や複雑なタスクの自動化を大きく変えつつあります。LAMs は包括的なツールとして、その価値を証明しています。
ここで、LAMs が活用される具体的な例を見てみましょう。
- ロボティクス:LAMs は、理解し応答できる、より賢く自律的なロボットを実現します。これにより、人とロボットのやり取りが進化し、製造業、医療、さらには宇宙探査における新たな自動化の可能性が開かれます。
- カスタマーサービスとサポート:顧客の問題を理解し、その場で解決アクションを取れるAIエージェントを想像してみてください。LAMs はチケット対応、返金、アカウント更新などのプロセスを効率化し、これを実現します。
- 金融:金融分野では、LAMs が専門的な知識に基づいて複雑なデータを分析し、投資や資産計画に対する個別の提案や自動化を行えます。
- 教育:LAMs は、生徒一人ひとりのニーズに応じたパーソナライズ学習体験を提供し、即時のフィードバックや課題の評価、適応型教材の生成を行うことで教育を変革します。
これらは、LAMs が産業を革新し、私たちの技術との関わりを向上させる方法の一部にすぎません。大型アクションモデルの研究開発はまだ初期段階にあり、今後さらに多くの可能性が広がっていくでしょう。
LAMの次は? #
大型アクションモデル(LAMs)は、私たちの技術との関わり方や、さまざまな分野でのタスク自動化のあり方を再定義する可能性を秘めています。指示を理解し、論理的に推論し、意思決定を行い、行動まで実行できるという独自の能力は大きな可能性を持っています。カスタマーサービスの強化から、ロボティクスや教育の革新まで、LAMs はAIエージェントが自然に生活に溶け込む未来を垣間見せてくれます。
研究が進むにつれ、LAMs はより高度化し、さらに複雑なタスクや専門領域の指示にも対応できるようになるでしょう。しかし、その力には責任が伴います。安全性、公平性、倫理的な利用を確保することが不可欠です。
訓練データに含まれる偏りや、悪用の可能性といった課題に取り組むことが、これらの強力なモデルを開発・展開する上で重要になります。LAMs の未来は明るいですが、その進化の過程で、より効率的で生産的、そして人間中心の技術社会の形成に貢献していくでしょう。
さいごに #
LAMと、その核心技術であるニューロシンボリックAIについて調べてみました。個人的な理解と考察は以下の通りです。
-
LAMの本質は「論理」と「学習」の融合
- LAMは、シンボリックAIが持つ「論理的な正しさを保証する力」と、ニューラルネットワークが持つ「曖昧なデータからパターンを学習する力」を組み合わせたものです。
- これにより、単に確率的にそれらしい応答をするLLMとは一線を画し、論理的なガードレールの中で自律的にタスクを実行できる可能性が生まれます。
-
LLM + Function Calling/ReActとの違い
- 現在主流のLLMエージェント(Function CallingやReActフレームワークを利用)もタスク実行は可能です。しかし、その思考(Reasoning)はLLMの言語能力に依存するため、論理的な破綻や幻覚(ハルシネーション)のリスクを常に伴います。
- 一方、LAMはシンボリックAIによって「これはAである、故にBをすべきだ」という論理的な推論が可能です。これにより、特にミッションクリティカルな業務において、より信頼性の高い自動化が期待できます。
シンボリックAIという概念は初めて知りましたが、現在のLLMが抱える課題を克服する鍵になるかもしれないと感じました。今後の発展が非常に楽しみな技術分野です。
Reply by Email